ABLE uses a set of heuristics to determine a files contents. The methods used include “magic” numbers (sequences of well known values at fixed offsets in the file) and common executable binary format headers. The overall approach is similar to the UNIX® file command which is provided with the ABLE shell built-in file command.
Once a files contents are identified ABLE will use the appropriate module to load and execute the file. If a unrecognised filetype or one for which no loader module is present, ABLE will report the error and return to the command line.
This file type is identified by the string “#!sh” in the first four bytes of the file. Such files are executed with the ABLE shell as detailed in Section 3.8, “Shell script”.
This file type is identified by the hexadecimal value AB1E0001 at the beginning of the executable file. This filetype is used for ABLE binary program extensions for code which it is not desirable to ship within ABLE because of space or licencing constraints. Examples of such programs are the romwrite reflash tool and batty test tool.
This file type is identified by the hexadecimal value 016F2818 thirty six bytes into the file. This file type is used for compressed LINUX® kernel images.
When a file of this type is executed ABLE sets up an appropriate parameter list and starts execution of the kernel image. Full details of the ARM LINUX® booting procedure can be found in the Booting ARM Linux document.
The ELF and AOUT binary file detection is provided for NetBSD and OpenBSD operation. The ELF header is detected from the hexadecimal value 464C457F at the beginning of the file and the various AOUT formats with several differing magic numbers (The AOUT types supported are the old “impure” format, the read-only text format, the “compact” demand load format and the demand load format.
When a file of this type is executed the relevant sections are loaded and relocated as described by their binary headers. The code is entered at its entry point with the MMU running and the parameters and command line passed as expected by the BSD kernel.
Although the LINUX® kernel can be extracted as an ELF object ABLE is unlikely to execute the image correctly, the zImage format should be used.
UNIX® compress files are identified by their first two bytes which contain 0x9D and 0x1F. These files when loaded (to be executed) are decompressed and the result file typed again.
Gzip files are identified by their header of 0x8B1F at the beginning of the file. These files when loaded (to be executed) are decompressed and the result file typed again.
These files are identified by various methods but all share the common property that they cannot be executed. These files must be manipulated with other commands such as the display command for images, the cat command for text and the dumpfile for data.
Files of this type are identified by their format which must be correct for the first few lines of the file. When loaded the whole file must be of the correct format.
The recognised S-Record format is well defined. Each file consists of a series of lines. Each line begins with an S character and is terminated by a newline. Each line represents an individual record, its type is determined by the second character on the line (0 to 9) followed by a record length, type dependant data and finally a checksum. All data after the type field is presented as 8 bit octets coded as two hexadecimal values e.g. the value 255 is presented as the text FF.
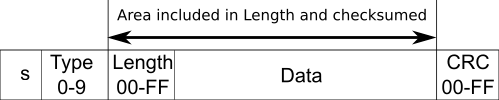
The checksum is calculated as a ones complement of the data octets including the length.
The header record is typically the first record in the file, ABLE does not interpret this record beyond printing the data section as ASCII output on the console. Any number of headers may be included as they have no impact on the decoding of the other lines.

The four byte (32 bit) addressed data record may be repeated as often as required to load all the program into memory. The four byte address gives access to the entire 4GB memory region of the ARM memory map. The address is specified as a physical location.

The four byte (32 bit) address end record is used to specify the address that execution will start from. The address is specified as a physical location. This record should only occur once at the end of the data.

During the parsing of an S-Record it is possible a syntax error in the input data may occur. If this happens an error report will be reported in the form:
error 1 on line 1
Table 6.1. S-Record loader error codes
| Code | Error |
|---|---|
| 1 | Line didn't start with S |
| 2 | Line finished before type |
| 3 | Type was not 0-9 |
| 4 | Line finished before length |
| 5 | Length field contained invalid characters |
| 6 | Line finished early in data |
| 7 | Data contained invalid characters |
| 8 | Checksum failed |
Where the errors refer to invalid characters this means characters
other than 0-9 and A-E were found in the line.
Example 6.5. An example S-Record
The S0 record starts the file. The S3 records contain the data. The S7 record contains the entry address and completes the file load.
S0030000FC . . S325000004403C0880018D08DD900000000011000026000000003C0880012508DC50C50000B401 S32500000460C50100B8C50200BCC50300C0C50400C4C50500C8C50600CCC50700D0C50800D4FA S32500000480C50900D8C50A00DCC50B00E0C50C00E4C50D00E8C50E00ECC50F00F0C51000F49A S325000004A0C51100F8C51200FCC5130100C5140104C5150108C516010CC5170110C518011434 . . S70500000000FA